A Pattern for Cross-Language Testing in Rust
This is the second part of a series of posts about rewriting Hypercore in Rust
There is little guidance on how to test Rust against code from other languages. After trying with several patterns, I found that the approach described here to be the most elegant.
I've been working on rewriting Hyperbee in Rust.
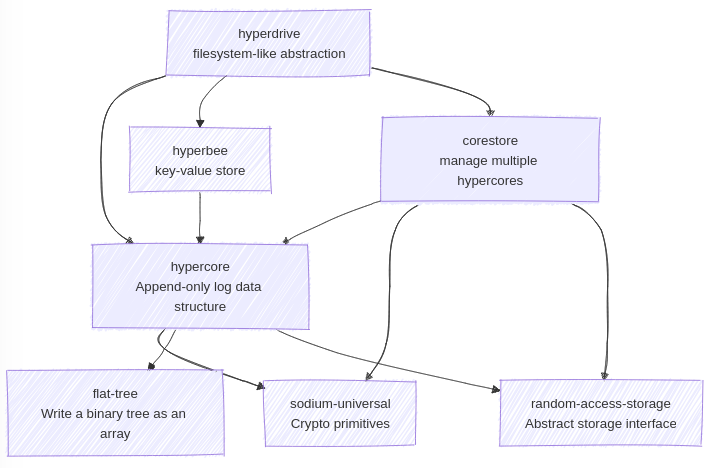
Hyperbee is a BTree built on Hypercore, a peer-to-peer append-only log, originally written in JavaScript.
I needed to be able to test my Rust code against the equivalent JavaScript.
I'm also creating a Python Hyperbee library, that wraps the Rust, and so I need to test Python against the equivalent Rust.
This is all part of the Rust Hypercore project which is working to rewrite all of Hypercore in Rust.
Another goal rewrite, is to be able to use Rust's excellent Foreign Function Interface (FFI) to create libraries for other languages, starting with Python.
So having a good pattern for cross language testing would prove useful throughout this project.
Key Benefits
No extra steps, just cargo test
Running your entire test suite through cargo test streamlines the testing process.
As long as you have the foreign language runtime and make installed, there's no additional setup needed.
This aligns with Rust developers' expectations - they're used to cargo test handling everything.
No need to to remember to run a separate command likepytest or npm test.
By avoiding these extra steps, we reduce friction and potential confusion in the development workflow.
Collocated Test Code
Writing foreign language test code directly within your Rust tests offers several advantages:
- Test code lives alongside the Rust code it's testing
- Clear documentation of test purpose through proximity
- No need to manage hard coded values
- Easy to extend tests as both implementations evolve
- Reduced overhead from switching between files
This organization makes the tests more maintainable and self-documenting. When you need to understand how a piece of Rust code interacts with Python or JavaScript, everything you need is in one place.
How it works
Lets start with an example directory structure taken from Hyperbeee.
# crate root tests/ # Integration tests directory py_tests.rs # Rust -> Python tests js_tests.rs # Rust -> JavaScript tests common/ Makefile # Makefile for non-language specific stuff vars.mk # Variables shared across Makefiles mod.rs # Rust module ... python/ # Python specifics Makefile # Run `make` to set up python dependencies mod.rs # python specific rust code ... # misc python files like requirements.txt javascript/ # JavaScript specifics Makefile # Run `make` to set up js dependencies mod.rs # javascript specific rust code ... # misc js files: package.json, node_module, etc
Here *_tests.rs are Rust tests. Each Rust test file is compiled as a crate, from those crates common/ is seen as a Rust module.
We will explain the innards of common later, but first we will start by looking at a test.
A Rust Test using Python
Let's dive into py_test.rs to see how this works
mod common; use common::{ python::{run_python}, Result, }; use hyperbee::Hyperbee; #[tokio::test] async fn hello_world() -> Result<()> { let storage_dir = tempfile::tempdir()?; { let hb = Hyperbee::from_storage_dir(&storage_dir).await?; hb.put(b"hello", Some(b"world")).await?; // drop `hb` so it does not lock `storage_dir` } let result = run_python(&format!( " async def main(): hb = await hyperbee_from_storage_dir('{}') res = await hb.get(b'hello') assert(res.value == b'world') ", storage_dir.path().display() ))?; assert_eq!(result.status.code(), Some(0)); Ok(()) }
The actual test part is simple
The Rust creates a Hyperbee and inserts the key b"hello" with value b"world", which is saved to storage_dir.
Then Python opens a Hyperbee with the same storage_dir, and checks for the key value.
The way the test works is more interesting.
At the top we declare mod common to make the common module available. We see this in the directory alongside py_test.rs. Within common we can have code exclusively for tests. We import common::python::{require_python, run_python}. These come from tests/common/python/mod.rs.
Rust code in the commod module is general purpose test code. Code within the python and javascript modules is language specific Rust code.
Building test dependencies
To understand what's going on we step into run_python:
/// Run the provided python `code` within a context where the Python Hyperbee library is imported. /// Code must be written within a `async main(): ...` function. pub fn run_python(code: &str) -> Result<Output, Box<dyn std::error::Error>> { require_python()?; run_code( &build_whole_script(PRE_SCRIPT, code, POST_SCRIPT), "script.py", build_command, vec![path_to_python_target()?, path_to_c_lib()?], ) }
The first thing do is call require_python.
This ensures that all the dependencies for running the python code are ready.
It looks like:
pub fn require_python() -> Result<Output, Box<dyn std::error::Error>> { run_make_from_dir_with_arg(REL_PATH_TO_HERE, "") }
It just calls run_make_from_dir_with_arg
pub fn run_make_from_dir_with_arg(dir: &str, arg: &str) -> Result<Output> { let path = join_paths!(git_root()?, dir); let cmd = format!("cd {path} && flock make.lock make {arg} && rm -f make.lock "); let out = check_cmd_output(Command::new("sh").arg("-c").arg(cmd).output()?)?; Ok(out) }
This handles calling make from a certain location, with some arguments.
Notice it makes use of flock.
This creates a lockfile while make is running, or, if the file exists, it blocks until it is deleted.
This lets us serialize all calls on the system to make.
Which is important because the tests are run in parallel, and many of them may be trying to run make.
So require_python ultimately calls make within test/common/python/ which uses the Makefile in the python/ directory.
We need to look at tests/common/python/Makefile to see what it does:
include ../vars.mk # Build the Python Hyperbee library $(TARGET_DEBUG_DIR)/hyperbee.py: $(C_LIB_PATH) cargo run -F ffi --bin uniffi-bindgen generate --library $(C_LIB_PATH) --language python --out-dir $(TARGET_DEBUG_DIR) # Pull in the $(C_LIB_PATH) rule include ../Makefile
First this gets some make variables defined in tests/common/vars.mk.
We then use some of these in the Makefile "rule" called $(TARGET_DEBUG_DIR)/hyperbee.py.
The rule should create the Python Hyperbee library at target/debug/hyperbee.py.
The "recipe" part shows how this file is made, by running uniffi-bingen.
Sidenote: we are using UniFFI for generating foreign language bindings.
It's cool! I'll discuss this more in a future post.
Notice that the rule has $(C_LIB_PATH) (target/debug/libhyperbee.so) as a dependency.
This rule is loaded in the include ../Makefile line, which is tests/common/Makefile.
That Makefile handles cross language dependencies.
We need to see haw it works:
# This file is loaded from other Makefile's so we can't use simple "include ../foo" because # that is resolved relative to the original Makefile. # # $(dir $(lastword $(MAKEFILE_LIST))) gets the dir of the current Makefile include $(dir $(lastword $(MAKEFILE_LIST)))vars.mk # Build Rust FFI library $(C_LIB_PATH): $(RS_SOURCES) $(ROOT)/Cargo.toml cd $(ROOT) && cargo build -F ffi
This rule creates libhyperbee.so by running cargo.
When libhyperbee.so8and hyperbee.py are ready, we have all the dependencies we need.
Now that the dependencies are ready, lets look at how we run the Python code.
Running the foreign code
We saw in the run_python function, that it is a wrapper around the run_code function.
The arguments run_code could use some explaining:
run_code( /// Create a string containing all the python code &build_whole_script(PRE_SCRIPT, code, POST_SCRIPT), /// The code goes in a file called "script.py" "script.py", /// A function creates a string, the string is the shell command that runs the code /// i.e. "python script.py" build_command, /// A vec of files copied next to "script.py" vec![path_to_python_target()?, path_to_c_lib()?], )
Let's see what run_code does:
/// Put the provided `code` into a file named `script_file_name` inside a temporary directory where /// `copy_dirs` are copied into. `build_command` should output a shell command as a string that /// runs the script. pub fn run_code( code: &str, script_file_name: &str, build_command: impl FnOnce(&str, &str) -> String, copy_dirs: Vec<PathBuf>, ) -> Result<Output> { let working_dir = tempfile::tempdir()?; let working_dir_path = working_dir.path().display().to_string(); let script_path = working_dir.path().join(script_file_name); write!(&File::create(&script_path)?, "{code}")?; // copy copy_dirs into working dir for dir in copy_dirs { let dir_cp_cmd = Command::new("cp") .arg("-r") .arg(&dir) .arg(&working_dir_path) .output()?; if dir_cp_cmd.status.code() != Some(0) { // handle error } } let cmd = build_command(&working_dir_path, &script_path.to_string_lossy()); Command::new("sh").arg("-c").arg(cmd).output() }
Essentially this is just a way to run a shell command (from build_command()), in a temporary directory, with code inside of a file named script_file_name, with some context (copy_dirs).
Putting this all together, when we call:
run_python(" async main(): run_python("print('hello world')) ")?;
We get a python script in a temporary directory (/tmp/.tmpDBK1j5/script.py) that looks like:
import asyncio from hyperbee import * async main(): run_python("print('hello world')) if __name__ == '__main__': asyncio.run(main())
hyperbee.py and libhyperbee.so are copied alongside script.py.
Finally python scrip.py is run.
The output of the process is returned by run_python as the Output type. This has the status code, stdout, and stderr.
You can check values using print in python, then in Rust checking Output.stdout for the result.
Generalizing to other Languages
You may see how this would work for another language.
In Hyperbee we apply the same pattern for JavaScript.
The specifics are in tests/common/js/*.
There I have a Makefile which handles setting up the JavaScript dependencies, so I can create a require_javascript function (like require_python).
Then in js/mod.rs I implement run_javascript around the run_code function.
For example there I would add a node_modules to the copy_dirs.
With these I'm able to write tests the same way I did with Python.
Why Makefiles for Dependencies
make may seem confusing at first, but It's at it's core are some very simple principles.
It is actually really powerful.
Sure there are some hacks in here, but:
-
makeis widely available and probably already installed on a developers machine. - It is language agnostic and provides a common interface for any language. Just run
make. - It's declarative dependency model is self documenting.
- It gives you incremental builds and caching. So we only rebuild what is needed.
I love make! But this is just a pattern.
You could use something else for handling dependencies.
But me, I love make!
Why use this module layout
The way module's work within tests/ was not well documented, or at least I could not find the documentation.
So I arrived at this after trying several things.
I knew that I wanted non-rust stuff like Makefiles, package.json, etc to live alongside their respective rust code.
So this would imply I should have a directory for each language.
You could imagine a more flat layout with js/, common/, and python/ all living under tests/.
But this has the problem that
then those modules could not see each other because tests/ is not actually a module.
The individual files within it are compiled as crates.
This has the effect that the layout of the modules tree depends on the test file itself, and so it could differ between test files.
Recall that mod python has a dependency on mod common.
So a test file that declares both mod python and mod common could work.
But a test file could just declare mod python, which would not work because common is not in the modules.
Putting all non-test /utility modules under a tree fixes this by making a single, correct, entry point.
Downsides and pitfalls
For a small project a better approach might be just hard coding your expected values into the tests. This pattern requires correctly implementing a way to run foreign code, and automatically pull foreign dependencies. This isn't super hard, but it should be done with care. Ideally these things could be extracted into library.
To that end, I've been working on building a library for running foreign code in Rust with rusty_nodejs_repl.
That library lets you write your states within a stateful Read-Eval-Print loop (REPL).
This lets you mutate and check state from Node.js throughout the test like this:
let mut repl = Config::build()?.start()?; let result = repl.run(" a = 42; console.log(a)").await?; assert_eq!(result, b"42\n"); // udate the state in the JavaScript let result = repl.run(" a = a*2 console.log(a)").await?; assert_eq!(result, b"84\n");
For examples of using this library see the Hypercore replicator library here.
If you have any questions or feedback, feel free to email me.. There is also a Discord Channel. If you'd like to contribute code, a good place to start is the Hypercore Rust project page. If you have more money than time, and want to support this work financially, consider contributing on my GitHub sponsors page.