Hypercore and Peer-to-Peer RSS
This first part of a series of posts about rewriting Hypercore in Rust
TL;DR This post describes my path through implementing a peer-to-peer RSS-like protocol with Hypercore in Node.js. Which motivated starting to work on a Rust Hypercore implementation. This also serves as a light introduction to Hypercore.
RSS and Hypercore
In late 2023 I had some extra time on my hands. I made a list of projects and interests that I might work on, and eventually settled on Hypercore, which I had heard it described as an append-only BitTorrent. I downloaded the whietpaper before a flight from L.A to Hong Kong. When I disembarked, I had decided I would try to use Hypercore to build a peer-to-peer RSS-like protocol.
RSS (or Atom), is a web-standard for creating and subscribing to a "feed" of updates. It is commonly used for distributing blogs and podcasts. Hypercore, being an append-only log, can provide something like a "feed" of data. Along with a way to share distribute updates in a peer-to-peer way. They seem like natural fit.
RSS's popularity has been waning in recent years as the way we get our "feeds" has been changing. Platforms (like Twitter, Youtube, Spotify, etc) prefer to keep users within their ecosystem, while pushing algorithmic feeds over chronological ones.
RSS's strength lies in aggregating content across platforms chronologically into one place. I believe there's room for a peer-to-peer alternative that preserves RSS's best qualities while adding modern distributed capabilities.
RSS's strength is that it allows you to aggregate your feeds across platforms into one place, and it chronological order, with a feed reader. Platforms don't like this, it makes users harder to track, advertise to, and lure into hours of scrolling. I think (or hope?) the pendulum will swing back to simple self-curated feeds when people get tired of being fed by an algorithm. I wanted a peer-to-peer RSS thing. Maybe other people do too. So I started working on it.
Implementation
I give a light introduction to Hypercore below and outline the implementation. If you just want to see the code, go here.
The Ecosystem
I don't recommend reading the white paper to get started, you should read the docs for that. To get started I needed to asses the ecosystem, look for prior work, libraries to use, etc. This was confusing so I'll summarize it here.
The project originally started as a thing called "Dat"; it was a way to share folders of large, mutable data in a peer-to-peer way. It came with a Node.js reference implementation. The original use-case was to solve the problem of link-rot for academic datasets. The peer-to-peer nature of Dat keeps data available because data is backed up by all peers; And because internally the data-structure is append-only, all history is preserved. So links are kept "alive" longer, and data behind a link cannot unexpectedly change.
At Dat's core it is the Hypercore append-only-log data-structure. A single Dat is composed several Hypercores combined to create a filesystem-like abstraction. Today this filesystem abstraction is contained in a library is called Hyperdrive. The project went through several iterations. Today the main Node.js implementation of Hypercore is being maintained and actively developed by Holepunch. Another important library to come out of Dat is a key-value store data structure called Hyperbee.
Here's a high-level dependency graph of Hypercore libraries.
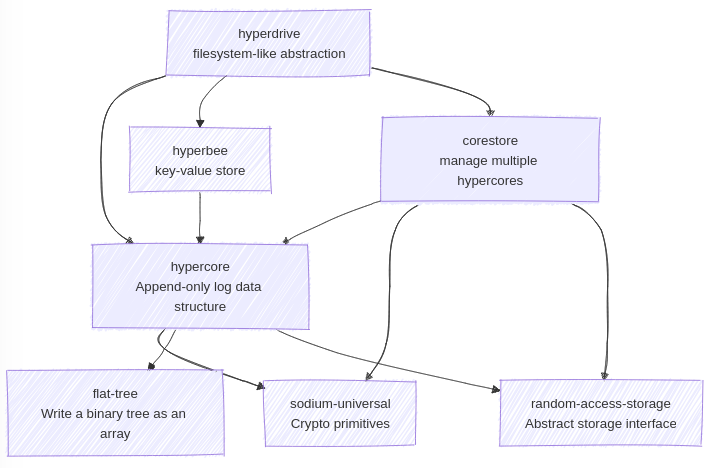
What is a Hypercore
It's helpful to understand more about Hypercore so we can understand of how to build something with it.
Hypercore's API is like array with a append and get methods.
In JavaScript this would be like Array with just the .push and .at methods.
Or in rust a Vec with .append and .get.
Not just anyone can call append.
When creating a Hypercore, it generates a key pair - the private key enables appending data, while the public key serves as a global identifier for peer discovery and allows peers to authenticate data.
Peers connect through end-to-end encrypted channels.
Since all data comes from the Hypercore authon, and all data is authenticated, this amounts to is only trusting the Hypercore author.
A key feature is sparse indexing - peers can efficiently download specific segments without requiring the entire dataset. So if there is a 100,000TB Hypercore dataset, you can efficiently download whatever small part of it you might want.
It was not obvious (to me) at first but you can do a lot with just append and get!
Hyperbee is a key value store built on Hypercore with O(log n) lookups.
I wrote a Rust implementation of Hyperbee. Read more about the algorithm here.
Building Hyper-RSS (HRSS) Peer
With those those basics we can dive into the implementation. For the core RSS feed-like data structure I wanted something like a "list" of "entries". Both the list and the entries should be able to carry some metadata (this could be: title, author, posted-at-time, etc). Each entry has a blob of data (this is the blog post, podcast, content, etc). It should be efficient and easy to get entries in reverse chronological order. I also need mutability for everything: metadata, entry-data, entry-ordering, etc.
For this I created OrderedHyperbee, which is a key-value store the preserves insertion order.
It is a wrapper around Hyperbee that key-prefixes to create different "sub-databases" to keep a mapping between index, key, and value.
This extra mapping between key and "index" lets us define an ordering.
By default a newly inserted item is last.
If a key is replaced it keeps it position"
Metadata is stored in it's own key-prefixed sub-database.
This has an API like:
class OrderedHyperbee { // get/set metadata async getMetadata(name) async putMetadata(name, value) // Insert a key & value in the last position async putOrderedItem(key, value) // Async generator over key value pairs from last to first async * getFeedStream() }
There also needed to be a way to store binary blobs outside of an entry's data.
Think of a podcast's RSS feed, it has an XML body which links to an audio file.
You wouldn't want to include this binary audio data in the entry data itself.
If you did, then loading a entry would potentially require loading a really big file.
We essentially need separate key-value store for binary data.
This is implmented in KeyedBlobs with the following API:
class KeyedBlobs { // Insert a blob with the given key async put(key, blob) // Get a whole blob getBlob (key) // Get a range of bytes within a blob with the given key getBlobRange(key, {start, end}) }
Up till now this has been agnostic to anything RSS specific.
Now we combine these things into a Peer, which serves as the base for Reader and Writer.
These are distinct because Writer needs to know how to write new items.
The current Writer implementation is totally based on converting an existing RSS feed into our format.
This may seems limiting at first, but it allows using any tool you would regularly use to author RSS feeds, to create a Hyper-RSS (HRSS) feed.
Writer contains the logic for taking an RSS entry downloading and extracting in media data, storing that in the KeyedBlobs, and rewriting links within the entry to point to KeyedBlobs; And saving the new entry in the OrderedHyperbee.
Writer is also able to diff RSS feeds to find new entries and add them, see Writer.updateFeed().
Now we need to use it for something
A Hyper-RSS Client
I've implemented a simple HRSS feed reader for testing. It is intended to used as desktop app, with a web view UI.
It's backend is in aggregator/ and the frontend is in web/.
It's ugly but it works! See the README.md to try to use it.
I have some RSS feeds I've been using for testing. I am able to automatically pull updates from xkcd, and display them, with alt text!
I'm also able to stream audio from podcasts.
This was surprisingly easy to implement on the backend.
It just required handling HTTP Range headers, which was done using KeyedBlobs.getBlobRange mentioned above.
Here it playing with Chapo Trap House.
Rewrite it in Rust
When I started building this, I quickly realized this would not really be useful except beyond a demo or experiment with Hypercore and RSS. Hypercore and it's Node.js libraries were great for making a demo. They're well built, it's suprisingly easy to build fairly complex and functional things with them.
However going demo, for HRSS to be actually useful, it has to broadly adopted, but relying on the Node.js libraries are an impediment toward that goal. It has to be a protocol that different things can speak across the internet. There needs to be an ecosystem of clients, authorship tools, libraries, HRSS indexes, etc. This is just an app.
Hypothetically, just as an example, suppose I went to the The Pirate Bay and asked them to support HRSS as a format for distributing TV series. Then (assuming they take me seriously at all) they would ask for a libraries and tooling to help them integrate the format. I can't give them this Node.js library because their backend is written PHP (I think).
Supposed they did implement HRSS, the next problem would be users need software to use HRSS. I could try to make everyone use my janky app, but a more successful adoption strategy would be integrating with existing RSS readers, podcast apps, or torrent clients. This brings us back to the problem of HRSS being written in Node.js, very few of the apps I'd want to integrate with written in Node.
This isn't just a problem with HRSS, it is a problem with the Hypercore ecosystem.
I'm not just hating on Node. For Hypercore to be successful it needs implementations across many platforms and languages. This led me to start working on the Hypercore Rust project. My goal is to complete use Rust's strong Foreign Function Interface(FFI) capabilities to generate bindings for multiple languages.
Rust Progress
I've made a lot of progress on the project in the past year. In that time I've: * Written Hyperbee from scratch. JavaScript version here. * Implemented the peer-to-peer replication protocol. JavaScript here. * Implemented Corestore. JavaScript here. * Implemented Hyperblobs. JavaScript here. * Pushed many changes upstream, some just fixes, others required for adding things like replication.
The last major part needed to before an entire Hypercore application can be built in rust is peer-discovery. The main JavaScript libraries required for this are Hyperswarm, Hyperdht, and dht-rpc. This work is on-going on GitHub here.
If you have any questions or feedback, feel free to email me.. There is also a Discord Channel. If you'd like to contribute code, a good place to start is the Hypercore Rust project page. If you have more money than time, and want to support this work financially, consider contributing on my GitHub sponsors page.
P.S. Suggestions for a better name than Hyper-RSS/HRSS are welcome!
Comments
Comments powered by Disqus